

Do you want your reports or dashboards to works fast?
Do you have a requirement to work fast with database operations?
Wants to know when a columnar DB is preferred?
Here you go for clarifications.
Columnar DBMS is a database management system (DBMS) that stores data tables by column rather than by row.
Practical use of a column store versus a row store differs little in the relational DBMS world. Both columnar and row databases can use traditional database query languages like SQL to load data and perform queries. Both row and columnar databases can become the backbone in a system to serve data.
However, by storing data in columns rather than rows, the database can more precisely access the data it needs to answer a query rather than scanning and discarding unwanted data in rows.
Columnar storage for database tables is an important factor in optimizing analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk.
The following series of illustrations describe how columnar data storage implements efficiencies and how that translates into efficiencies when retrieving data into memory.
Let's take an example with a table and its internal storage structure to understand more about it.
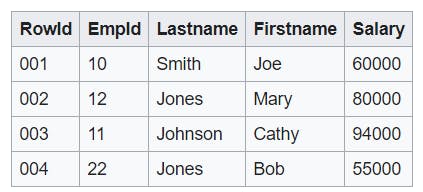
This first illustration shows how records from database tables are typically stored into disk blocks by row.
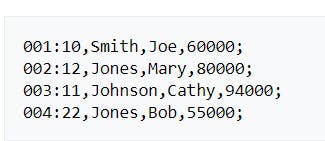
A columnar database stores data in columns whereas other popular databases like Postgres, MySQL, Oracle etc. uses traditional row-based data storage.
The next illustration shows how with columnar storage, the values for each column are stored sequentially into disk blocks.
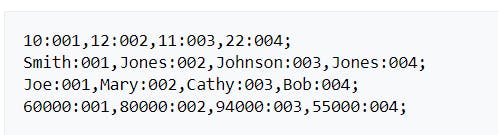
Using columnar storage, each data block stores values of a single column for multiple rows. As records enter the system, Amazon Redshift transparently converts the data to columnar storage for each of the columns.
More importantly, columnar databases are designed to read data more efficiently and return queries with greater speed so it is better to use the columnar databases whenever you have more read operations. It will not perform well for insert or update operations.
Here is the typical diagram of the storage structure of columnar vs row structured storage
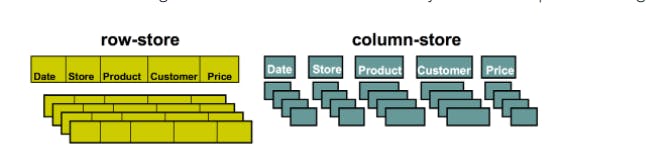
In a typical relational database table, each row contains field values for a single record. In row-wise database storage, data blocks store values sequentially for each consecutive column making up the entire row. If block size is smaller than the size of a record, storage for an entire record may take more than one block. If block size is larger than the size of a record, storage for an entire record may take less than one block, resulting in an inefficient use of disk space. In online transaction processing (OLTP) applications, most transactions involve frequently reading and writing all of the values for entire records, typically one record or a small number of records at a time. As a result, row-wise storage is optimal for OLTP databases.
In this simplified example, using columnar storage, each data block holds column field values for as many as three times as many records as row-based storage. This means that reading the same number of column field values for the same number of records requires a third of the I/O operations compared to row-wise storage. In practice, using tables with very large numbers of columns and very large row counts, storage efficiency is even greater.
The columnar databases are best suitable for analytics hence people says that it is fututure of business intelligence why because it allows faster results for the people so that they can take immediate actions.
Here analytics like reports or dashboards which are created on data and 99% of analytics use different kinds of reading queries rather than any kind of write operations hence columnar databases are becoming popular on these dates.
few tradictional relational databases also uses coumnar storage structure but not popular in doing it example for it MS-SQL.
The high-speed searching, scanning, and aggregation capabilities of columnar storage are awesome for analytics, however, which is why columnar stores are very popular in these environments.Columnar databases are much faster than row oriented databases for many analytical operations. But they are generally not faster in a database with a significant number of write operations. They are also generally not faster when a database is used more often to read information about a small number of records at a time, like a CRM or ERP application.
A relational database is ideal for transactional applications because it stores rows of data.
A columnar database is preferred for analytical applications because it allows for fast retrieval of columns of data. Columnar databases are designed for data warehousing and big data processing because they scale using distributed clusters of low-cost hardware to increase throughput.
This is why columnar databases are often used in reporting databases, but rarely used in more real time databases.
These are some common column-oriented databases:
Let put advantages and disadvantages of it.
Advantages
- faster retrieval performance
- stores data as blocks for each column hence less compressed storage
- Queries that involve only a few columns
- Aggregation queries against vast amounts of data
- Column-wise compression
- data store under column hence column meta data also stores
Disadvantages
- slower writing or updating data
- Incremental data loading
- Online Transaction Processing (OLTP) usage
- Queries against only a few rows
Conclusion
Column Oriented databases came out with a 2005 paper explaining the design all built upon. This column-oriented database is being used by most major providers of cloud data warehouses. This has become the dominant architecture in relational databases to support OLAP and it is best suited for analytics and scaling.
Thanks for reading it.